| Pages in topic: [1 2] > |
Déjà Vu's Lexicon is called Project Glossary in CafeTran Espresso Thread poster: Hans Lenting
|
|---|
For those who consider to migrate from Déjà Vu to CafeTran Espresso: Déjà Vu's Lexicon is called Project Glossary in CafeTran Espresso. It will be automatically created when the corresponding checkbox in the Dashboard is selected.
In contrast to Déjà Vu's Lexicon, CafeTran Espresso's glossaries allow:
- Adding synonyms or alternative translations
- Adding alternative source terms (source term nests)
- Setting three different levels of prio
... See more For those who consider to migrate from Déjà Vu to CafeTran Espresso: Déjà Vu's Lexicon is called Project Glossary in CafeTran Espresso. It will be automatically created when the corresponding checkbox in the Dashboard is selected.
In contrast to Déjà Vu's Lexicon, CafeTran Espresso's glossaries allow:
- Adding synonyms or alternative translations
- Adding alternative source terms (source term nests)
- Setting three different levels of priority
- Quickly adding related term pairs in one go
- Adding new terms to the custom dictionary
▲ Collapse
| | | |
Michael Beijer 
United Kingdom
Local time: 21:47
Member (2009)
Dutch to English
+ ...
| memoQ’s version of Déjà Vu’s great ‘Lexicon’ feature | Jan 14, 2021 |
Hi Hans,
Some other CAT tools now also have features similar to Déjà Vu's great Lexicon.
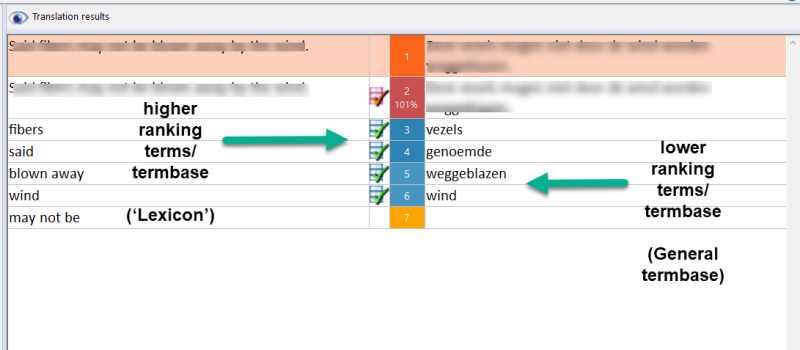
memoQ, e.g., allows you to assign rankings to termbases (higher or lower). You can also send terms to a particular termbase while translating with a specific shortcut.
Higher ranking term matches in the ‘Translation results’ window are shown in a darker blue, which makes them stand out nicely.
In the ‘Translation results settings’ dialogue, you ... See more Hi Hans,
Some other CAT tools now also have features similar to Déjà Vu's great Lexicon.
memoQ, e.g., allows you to assign rankings to termbases (higher or lower). You can also send terms to a particular termbase while translating with a specific shortcut.
Higher ranking term matches in the ‘Translation results’ window are shown in a darker blue, which makes them stand out nicely.
In the ‘Translation results settings’ dialogue, you can also specify that these darker blue matches are shown above any lower ranking (lighter blue) matches in the ‘Translation results’ window.

Michael ▲ Collapse
| | | |
| DVX Lexicon VS CafeTran/MemoQ | Feb 22, 2021 |
Would be interesting to know if both also support or expand the more advanced DVX Lexicon toolset, such as:
1. Create/Resolve/Remove
2. Import/Export
3. Add to TB/TM
Cheers,
Denis
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | As simple as possible | Feb 22, 2021 |
Denis Danchenko wrote:
Would be interesting to know if both also support or expand the more advanced DVX Lexicon toolset, such as:
1. Create/Resolve/Remove
2. Import/Export
3. Add to TB/TM
Cheers,
Denis
For a better understanding of the way how CafeTran Espresso handles glossaries, it is important to know that these are plain text, tab-delimited files.
I'll try to answer your questions:
- Creation: automatic creation via the Dashboard during project configuration. Or manual creation at any time.
- Remove: removal of term pairs via the Term edit dialogue box, or by opening the glossary via the context menu in a universal text editor.
- Import/Export: not necessary, since the glossaries are plain text, tab-delimited files.
- Adding to TB: these are called glossaries in CafeTran Espresso. You can merge glossaries via a dedicated menu item. Or you can simply glue them together in a universal text editor.
- Adding to TM: You can add the content of glossaries to Memories via a dedicated menu item. (BTW: The other way around, Memory > Glossary, is supported too.)
From the Déjà Vu manual:
Resolving:
After the lexicon has been built and you have added and removed those entries you considered necessary, you should translate it. You can do this manually, but you can also decide to use the content in your databases.
If I understand correctly, resolving is about adding target language content to a thesaurus in the source language, in order to create term pairs/a glossary.
Personally, I add all term pairs on the fly, during the translation process. I often review my initial choices (which is very handy in CafeTran Espresso, since the glossaries are plain text, tab-delimited files and the software has a great feature in the Find and Replace dialogue box to simultaneously adapt segments in the project and memories, or in the glossary).
If, however, you want to create a thesaurus first, you can use one of the dedicated features in the Task menu:
On a side note:
In the old days, when computers were not so powerful, CAT programs had to index word and phrase lists in order to search them quickly. With today's powerful computers, this is not necessary anymore. Glossaries and Memories in plain text have many advantages. You don't have to import or export them and you can edit them directly*) in a text editor. Time savings and comfort. *) For example, deduplication, spelling check, global search and replace.
[Edited at 2021-02-22 10:48 GMT]
| | |
|
|
|
| #As simple as possible | Feb 22, 2021 |
Dear Hans,
Thanks a lot for your quick reply and the detailed explanation.
I'll have a closer look at how CafeTran could improve my data routines, which are mostly DVX-drven.
A quick follow-up question to address data handling on a larger scale:
While I find the CafeTran's focus on plain text really comfy, any chance I could use it to leverage (meta)data in a way similar to SQL in DVX?
Cheers,
Denis
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER
Denis Danchenko wrote:
While I find the CafeTran's focus on plain text really comfy, any chance I could use it to leverage (meta)data in a way similar to SQL in DVX?
My largest glossary is 440 000 term pairs (the IATE). It is loaded together with my own created Big Papa (or was it Big Mama) glossary of 130 000 term pairs. There is no lag, all searches are instaneously. Edits do of course take a second (or 2), that's why I add new terminology to a dedicated glossary, that I merge regularly with my own big glossary. CafeTran Espresso offers a nice feature set for this glossary maintenance, including sorting on length and merging alternative translations (multiple target terms) to one source term, defining the newest target term as the one that auto-assembling has to use. This is a great way to optimise your glossaries for A-A.
I don't use big memories: I have one memory per client. So I'm not a user of CafeTran Espresso's solution for big memories: the Total Recall database technology:
https://cafetran.freshdesk.com/support/solutions/folders/6000058183
You can use an SQL driver for TC:
https://cafetran.freshdesk.com/support/solutions/articles/6000152599-total-recall-with-mysql-database
| | | |
Dear Hans,
I'm quite happy with how the Assemble feature works in DVX and I'm not sure I'd benefit from using the stack of context-bound terms [using LOCK as a verb/noun OR as a base term/modifier] to improve the quality of assembled translations.
An option to run plain-text S&R across projects/TM's/TB's is what I seriously miss in DVX though.
On the other hand, SQL works great for what I call 'static maintenance' of datasets using metadata [domain/ client/project/file V... See more Dear Hans,
I'm quite happy with how the Assemble feature works in DVX and I'm not sure I'd benefit from using the stack of context-bound terms [using LOCK as a verb/noun OR as a base term/modifier] to improve the quality of assembled translations.
An option to run plain-text S&R across projects/TM's/TB's is what I seriously miss in DVX though.
On the other hand, SQL works great for what I call 'static maintenance' of datasets using metadata [domain/ client/project/file VS user/date].
Cheers,
Denis ▲ Collapse
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | SQL & maintenance | Feb 24, 2021 |
Denis Danchenko wrote:
On the other hand, SQL works great for what I call 'static maintenance' of datasets using metadata [domain/ client/project/file VS user/date].
This should be possible with the SQL in Total Recall too ...
BTW: The developer is very responsive to users' requests. So if you are missing anything regarding the SQL implementation, you could request an enhancement. CafeTran Espresso is actively being developed.
| | |
|
|
|
| CafeTran enhancements | Feb 24, 2021 |
Hans Lenting wrote: Denis Danchenko wrote:
On the other hand, SQL works great for what I call 'static maintenance' of datasets using metadata [domain/ client/project/file VS user/date].
This should be possible with the SQL in Total Recall too ... BTW: The developer is very responsive to users' requests. So if you are missing anything regarding the SQL implementation, you could request an enhancement. CafeTran Espresso is actively being developed.
I've touched on SQL here since we've discussed data maintenance as applied to overlaps and extensions of the Lexicon/Project Glossary concepts.
A more comprehensive A-wishlist I'd request implementing in CafeTran to consider re-investing in this otherwise very powerful tool would be:
- DeepMiner-like autosuggest technology mining sub-segment data from all attached datasets.
- Morphology support (aka Custom mark-up in MemoQ) for more intelligent terminology QA.
- SQL or alternative toolset for intra-project and inter-project TM/TB maintenance.
I apologize in advance if I've overlooked or missed any of these in the recent CafeTran upgrades. As I've not upgraded CafeTran since 2015.
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | I need some assistance | Feb 25, 2021 |
Denis Danchenko wrote:
- DeepMiner-like autosuggest technology mining sub-segment data from all attached datasets.
- Morphology support (aka Custom mark-up in MemoQ) for more intelligent terminology QA.
- SQL or alternative toolset for intra-project and inter-project TM/TB maintenance.
I apologize in advance if I've overlooked or missed any of these in the recent CafeTran upgrades. As I've not upgraded CafeTran since 2015.
Can you make a demo project, e.g. EN > D, with some DM suggestions illustrated in screenshots? I'll try to replicate them in CafeTran Espresso, since I think that its fragment matching is pretty much the same.
Thank you in advance!
Re: Morphology support, can you give some examples?
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER |
Exactly TME marks up word forms to be tuned out by MemoQ with pipes/asterisks on the QA step. TME marks up word forms to be tuned out by MemoQ with pipes/asterisks on the QA step.
Fewer false positives, faster QA, better data.
DVX is not of much help here.
I'll share the screenshots with DM at work by MON/TUE.
Have a good weekend,
Denis
[Edited at 2021-02-26 09:02 GMT]
| | |
|
|
|
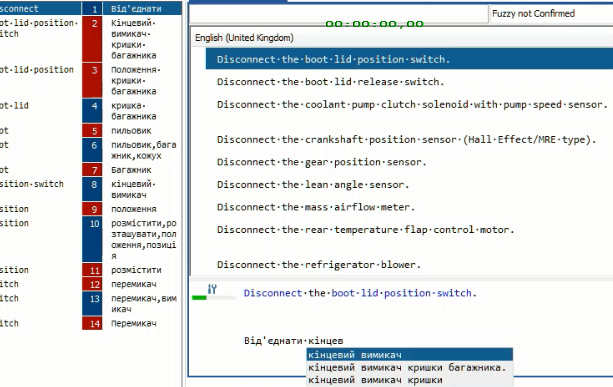
I've attached a screen with an Autowrite autosuggest list in the active segment.
It includes:
- a termbase match at the top (Pos 8 in AutoSearch)
- a TM subsegment match in the middle (Pos 2 in AutoSearch)
- a deep-mined phrase at the bottom.
Please note that the latter is generated 'on the fly' rather than by using direct TM/termbase input.
DeepMiner makes even low-count text data readily available and helps translate in line with the Iconic Linkage concept [J. Byrne, 2006].
| | | |
| DeepMiner: better example | Mar 2, 2021 |
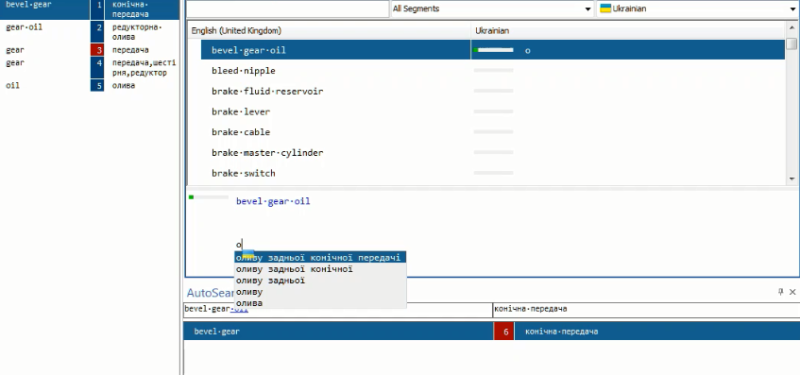
Here's a better example of 'deep mining' in Deja Vu:
As I type the first letter, DM comes up with a very close hit, even though the translation is not prompted by AutoSearch [bottom/left].
The Fuzzy Match score has been set to 50%.
Alternatively, I could 'assemble' the translation from termbase matches (pos 1 and 5), but this would involve an extra keystroke + larger post-editing effort.
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | Cannot replicate | Mar 6, 2021 |
Thanks for your postings, but due to lack of knowledge of the target language I cannot verify how CT would handle this.
[Edited at 2021-03-06 07:58 GMT]
| | | |
| Pages in topic: [1 2] > |







